The ScreenToWorld Transform
This article describes the problem of doing the Screen-to-World projection, from theory to practice. In this article vectors and matrices are written in bold, vector elements are written as subscripts and it assumes Direct3D conventions.
DEFINITION: Let $\mathbf{WorldToScreen}(x,y,z) : {\Bbb R}^3 \rightarrow {\Bbb R}^2$ be the function that converts a position from 3D world space to the corresponding 2D position on the screen. Can the inverse of this function, $\mathbf{ScreenToWorld}(x,y)$ be defined? For a function to have an inverse, it must be bijective (a.k.a. one-to-one & onto). In fact, “having an inverse” and “being bijective” are equivalent properties.
However, as it is defined, WorldToScreen is not one-to-one. Consider the fact that a ScreenToWorld function would need to take a 2D input and output a 3D position, we are missing 1 whole dimension of information! Also consider this visual example:
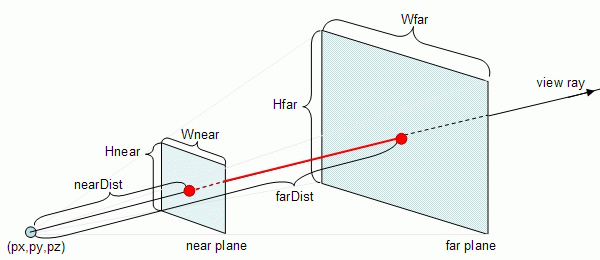
the image shows the camera position at (px,py,pz) and its view frustum, with a red ray passing through the near and far planes. All the points on the red ray collapse on the same pixel position (X,Y). So when you input in ScreenToWorld the (X,Y) and ask “what is the corresponding 3D position”, the answer actually lies on a ray stretching from the near plane to the far plane. Let’s parameterize this ray as $\mathbf{l}(d) = \mathbf{p} + d \cdot \mathbf{v},\text{ }d \in [n,f]$. Where p is the camera position, v is the ray direction and d is a value from the near-plane to the far-plane. we call $d$ the depth; plugging in $d$ will give us a specific point along the ray. Thus, we must know $d$ if we want a specific position along the ray.
[Video] The depth of each pixel on the view frustum, visualized; the depth is not perceived by the viewer
With that in mind, lets redefine WorldToScreen.
DEFINITION: $\text{Let } \mathbf{WorldToScreen}(x,y,z) : {\Bbb R}^3 \rightarrow {\Bbb R}^3$ be the function that takes as input a 3D world position and outputs (X,Y,d) where (X,Y) is the screen position and d is the depth.
Now that we have 3 dimensions of freedom, the function is invertible. This transformation is actually a combination of 4x4 Matrices (duh - we are doing real time graphics here).
To simplify the equation, I will leave the result in NDC space rather than Screen-Space but dont worry the conversion between the two is easy and shown later. NDC is the same as screenspace but the region is a [-1, 1] x [-1, 1] x [0,1] box rather than a
(width x height) rectangle.
A WorldToScreen transform is implemented as:
$$ \mathbf{ToClip}(x,y,z) = \mathbf{PV} \begin{bmatrix} x&y&z&1 \end{bmatrix}^T \\ \mathbf{WorldToScreen}(x,y,z) = \frac{\mathbf{ToClip}(x,y,z)_{xyz}} {ToClip(x,y,z)_w} $$
where P is the 4x4 projection matrix and V is the 4x4 view matrix.
We can finally define ScreenToWorld.
DEFINITION: $\text{Let } \mathbf{ScreenToWorld}(x,y,d) : {\Bbb R}^3 \rightarrow {\Bbb R}^3$ be the function that converts a point from Screen-Space to World-Space. This function exists and is defined as:
$$ \mathbf{ToWorld}(x,y,d) = \mathbf{V^{-1} P^{-1}} \begin{bmatrix} x&y&d&1 \end{bmatrix}^T \\ \mathbf{ScreenToWorld}(x,y,d) = \frac{\mathbf{ToWorld}(x,y,d)_{xyz}}{ToWorld(x,y,d)_w} $$
where $\mathbf{V^{-1}}$ is the inverse of the view matrix and $\mathbf{P^{-1}}$ is the inverse of the projection matrix. Notice also how the order of the matrix transformations are in reverse order.
We will now test if this works. I personally do not have a graphics engine (yet) to try this on so I will use someone else’s, specifically I will use Riot’s “League of Legends” game. Without going too deep into the details, League uses Direct3D as the backend, so I will redirect control flow from IDXGISwapChain::Present to my own injected dynamic library and do my draw call. Present is the last thing called in the rendering pipeline so everything - including the depth buffer - has been cleared by then. for this reason we will also redirect the flow from ID3D11DeviceContext::ClearDepthStencilView which exposes a pointer to the depth buffer right before its cleared. The depth buffer will give us the $d$ value that we want for every (x,y) pixel position
For our test, I will draw a full screen quad, do a ScreenToWorld transform on every pixel and if the outputted worldPos is close to my mouse cursor regardless of world height, I will draw that pixel (overwritte the engine’s), else I will discard it (keep the engine’s pixel).
float3 ScreenToWorld(float x, float y, float d) {
y = 1.f - y;
float3 ndcPos = float3(x * 2.0 - 1.0, y * 2.0 - 1.0, d); //UV to ndc
float4 clipPos = float4(ndcPos, 1.f); //NDC == Clip when w = 1
float4 worldPos = mul(clipPos, c_InvViewProj);
return worldPos.xyz / worldPos.w;
}
float4 main(PS_INPUT input) : SV_TARGET
{
float d = depth.Sample(sampler, input.uv);
float3 worldPos = ScreenToWorld(input.uv.x, input.uv.y, d);
float2 localPos = worldPos.xz - c_MouseWorldPos.xz;
float radius = 300.f;
if (length(localPos) < radius)
{
float2 newUV = (localPos / radius) * 0.5 + 0.5;
newUV.y = 1.f - newUV.y;
return input.color * SampleTexture(newUV);
}
return float4(0.f,0.f,0.f,0.f);
}
It works Perfectly, but this method has one main drawback: We need to know the depth of the pixel. Now if you are working in a shader (like in this case) this isnt an issue, because on the GPU the exact depth of each pixel is stored in the depth buffer which is easily accessable, but what if we are working on the CPU and we want to do a ScreenToWorld? Copying the depth buffer from GPU VRAM to CPU RAM is too costly for it to be an option.
For the CPU sided ScreenToWorld, we can try to cast a ray from the camera to the scene until the ray hits terrain (like the red ray in the image above). Now the condition for when that happens is somewhat game specific, here in League the camera looks down towards the terrain so the obvious condition is when the ray y position (height) has dipped below the terrain height.
There is a function that gives us the terrain height for a specific position so we are going to use that. A ray can be casted in any space (ndc space, view space, world space etc), here we are going to cast it in world-space because we need the ray to be in worldspace to sample the terrain height.
Vector3 Renderer::ScreenToWorld(Vector2 screenPos)
{
//Screen -> Clip
float x = (2.0f * screenPos.x) / gameWidth - 1.0f;
float y = 1.0f - (2.0f * screenPos.y) / gameHeight;
float z = 1.0f;
DirectX::XMVECTOR rayClip = DirectX::XMVectorSet(x, y, z, 1.f);
DirectX::XMMATRIX invProj = DirectX::XMMatrixInverse(nullptr, GetProjectionMatrix());
//Clip ->View
DirectX::XMVECTOR rayEye = DirectX::XMVector4Transform(rayClip, invProj);
rayEye = DirectX::XMVectorSet(rayEye.m128_f32[0], rayEye.m128_f32[1], 1.f, 0.f);
DirectX::XMMATRIX invView = DirectX::XMMatrixInverse(nullptr, GetViewMatrix());
//View->World
DirectX::XMVECTOR rayWorld = DirectX::XMVector4Transform(rayEye, invView);
rayWorld = DirectX::XMVector3Normalize(rayWorld); //its a directional vector so we normalize it.
Vector3 v = Vector3(rayWorld.m128_f32[0], rayWorld.m128_f32[1], rayWorld.m128_f32[2]);
Vector3 p = *(Vector3*)&invView.r[3].m128_f32; //camera position is stored at the bottom row.
const int maxAttempts = 150;
const float stepSize = 25.f;
for (int i = 0; i < maxAttempts; i++)
{
Vector3 posOnRay = p + v * (i * stepSize);
float height = core.navMesh.GetHeightPos(posOnRay);
if (posOnRay.y < height)
{
return posOnRay;
}
}
Vector3 farthest = p + v * (maxAttempts * stepSize);
return farthest;
}
I will test it out on my mouse cursor to find its world position and then compare it to the game’s mouse world position.
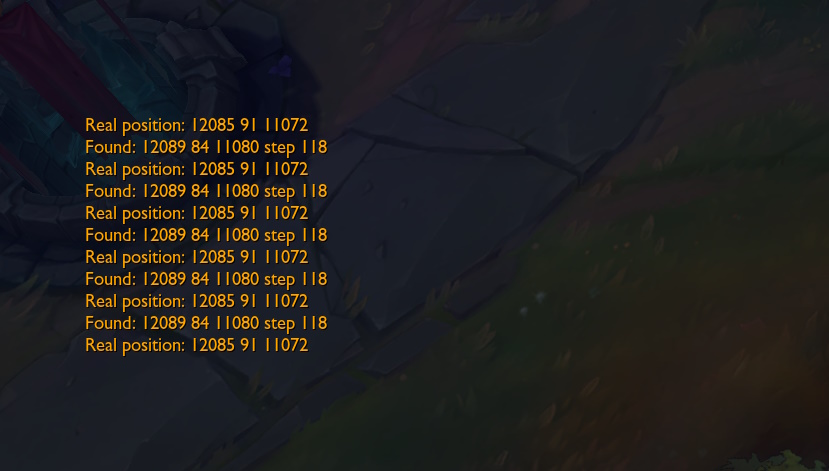
And as you can see its very close to the actual result, reducing the step size and increasing the attempts will increase the accuracy. The function can be made much faster by doing a binary search rather than a linear search.
While in the pixel shader in the previous example we worked with UV and NDC coordinates, here in the CPU our input are actual screen coordinates so we converted those to clip space first.